MMDet框架
1. 安装MMCV
OpenMMLab是商汤贡献到 OpenI 启智社区的国产人工智能视觉算法框架,而MMCV是openMMLab的一些列框架的基础支持库,例如目标检测框架的MMDetection、语义分割MMSegmentation和姿态估计的MMPose等等视觉算法框架都依赖于MMCV。
之前OpenMMLab官方只有liunx版本的编译包,在自己笔记本上装双系统其实也比较麻烦,需要重新配置一遍cuda和torch,并且要安装显卡驱动,还有一点就是liunx的桌面发行版时不时就会崩一下,搞的人很头疼,况且在自己电脑上安装mmdetection充其量也就是把程序调通,最后还是得上GPU服务器,只是为了调通程序就装个双系统,感觉得不偿失,但是在windows上安装mmcv的话需要自行编译并且步骤相当的繁琐,好在去年12月份,OpenMMLab官方发布了Windows版本的预编译包,一句话就能将MMCV安装上。
我笔记本上的cuda是11.1,torch为1.9.0。这里就根据自己的情况替换,执行命令就可以下载预编译包,自动安装mmcv了。
1 | pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html |
如果安装失败,请尝试手动编译mmcv,此处附上一个详细教程。
(1条消息) 安装Open-MMlab 的 MMPose 和 MMCV_炼丹狮的博客-CSDN博客
2. 安装编译环境
虽然mmcv不需要手动编译,但是后面安装openmim,以及安装MMDetection,也就是执行pip install -v -e .此命令的时候依然需要编译环境,因为这里依赖一个pycocotools的包,这个包只能是编译完成,当然如果一般情况下使用pycocotools只需要pip install pycocotools-windows的命令直接安装就行,但是貌似这两个不是一个包,或者因为版本问题吧,我已经安装过pycocotools-windows,但是依然报错,所以我才安装了编译环境,这里的编译环境使用的是visual studio 2019的c++编译环境,虽然这玩意很占磁盘空间,但是没办法,只好硬着头皮上了,此处我参考的OpenMMLab的这个知乎博文的第三部分。Windows 环境从零安装 mmcv-full - 知乎 (zhihu.com)。也就是编译环境安装的部分。
1 | https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/ |
我按照官方的说明,下载的visual Studio 2019,当然这里下载2022应该也没啥问题。
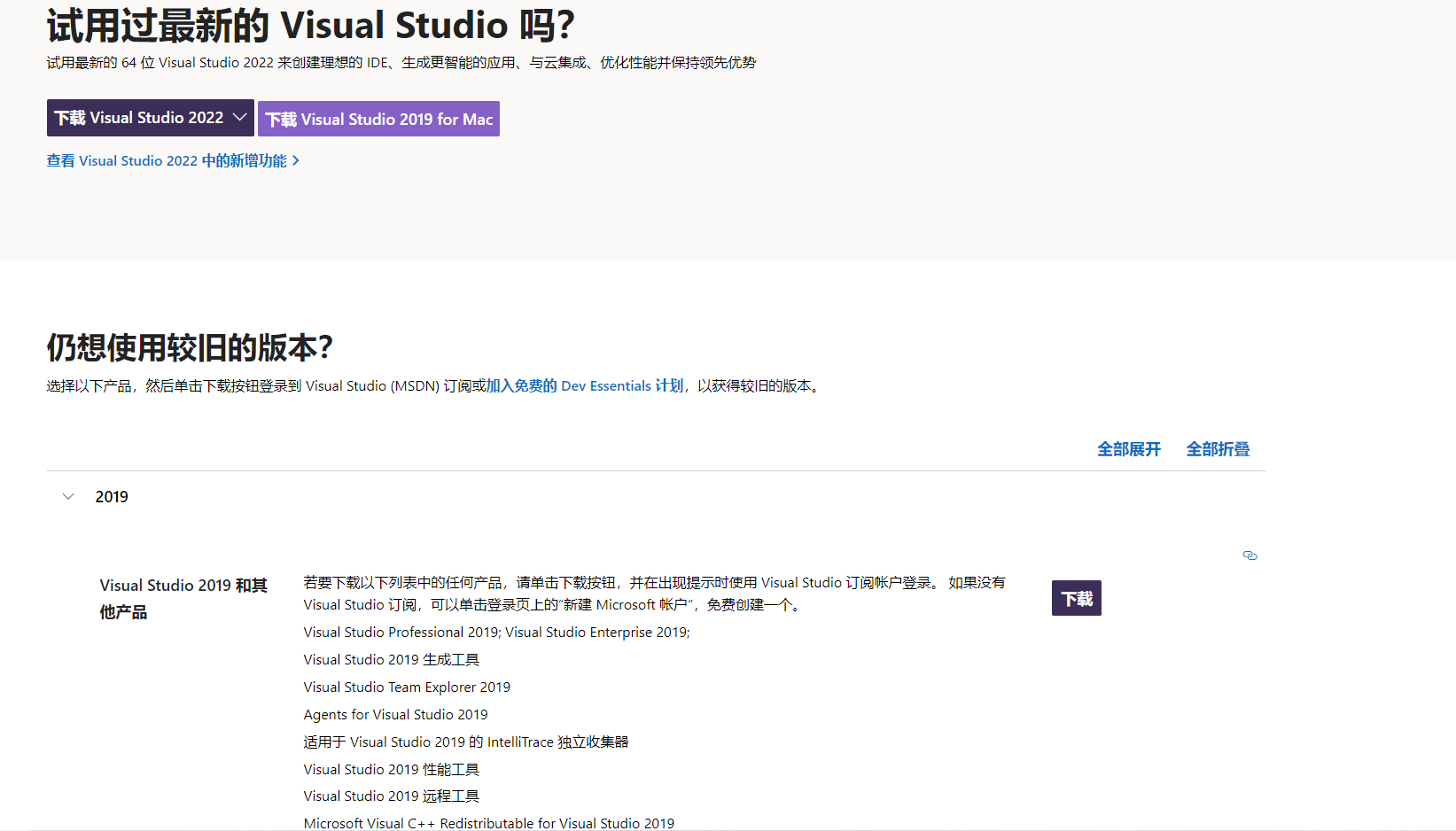
然后运行下载的exe文件,之后选择使用C++(下图来自上面OpenMMLab官方知乎号)。
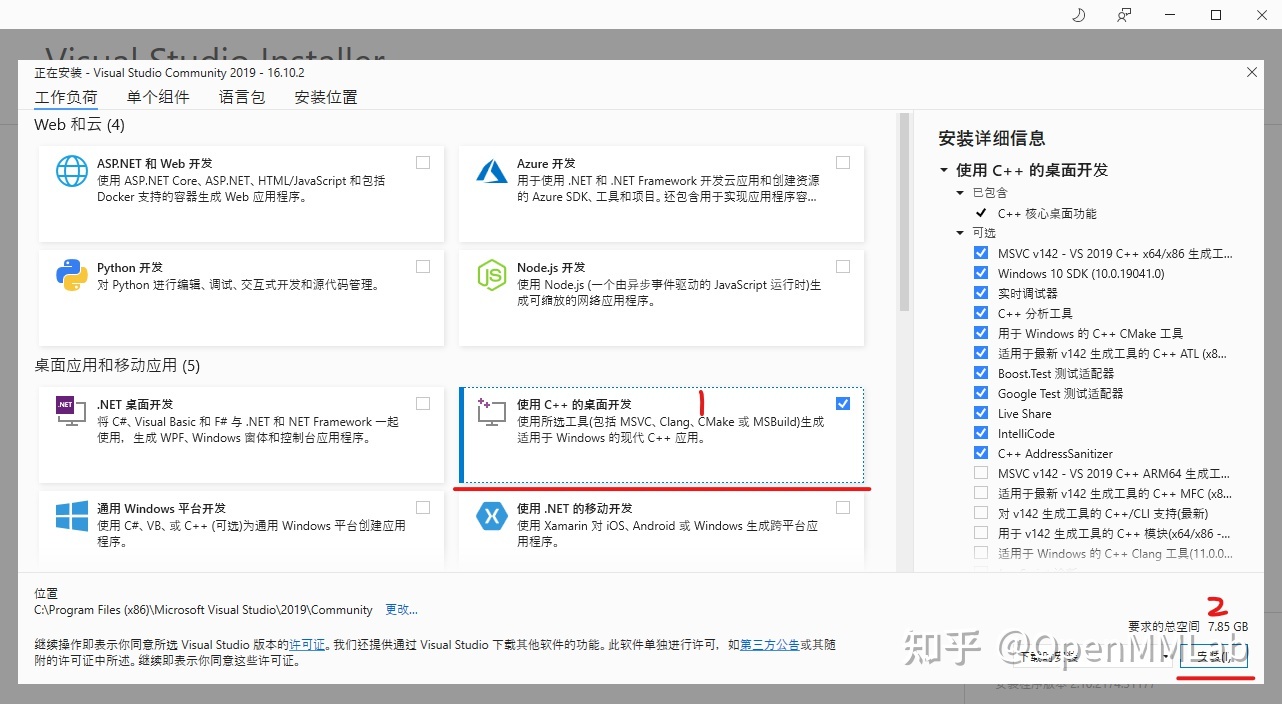
安装需要下载一些编译程序,要等一会。安装完成后按照下图设置环境变量(切记 14.29.30133 需换成自己的版本号)。(下图来自OpenMMLab官方知乎)
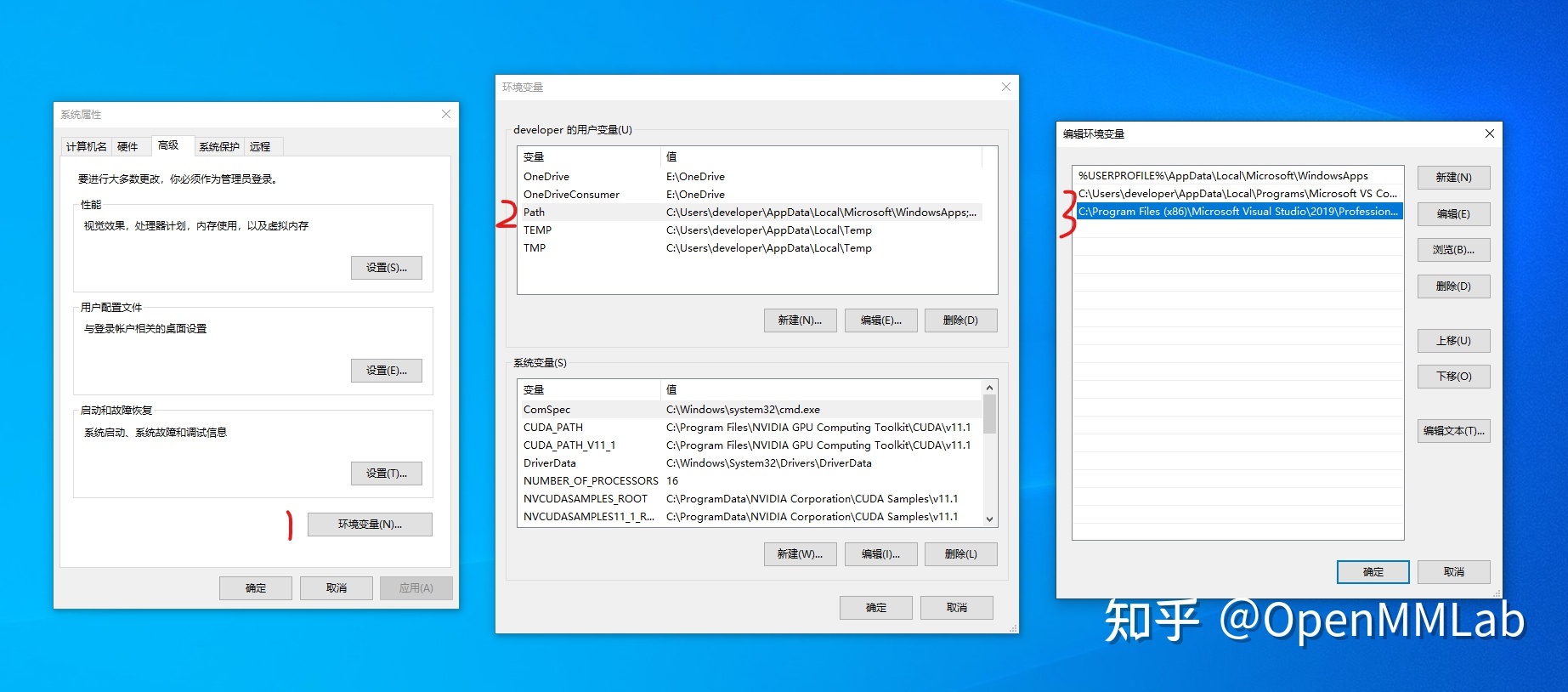
有点奇怪的是,我并没有设置环境变量就编译成功了,我是在写这个博文的时候才想起来要设置环境变量。
3. 下载并安装MMDetection框架包
有了mmcv之后,就可以直接安装MMDetection了,这里的前提是已经创建好了conda虚拟环境并且安装好了cuda和torch。
打开git,切换到自己的workspace或者git的文件夹下。
1 | git clone https://github.com/open-mmlab/mmdetection.git |
将所依赖的包全部安装好,并安装MMDetection。这里如果没有安装好编译环境的话,就会报下面这个错误。 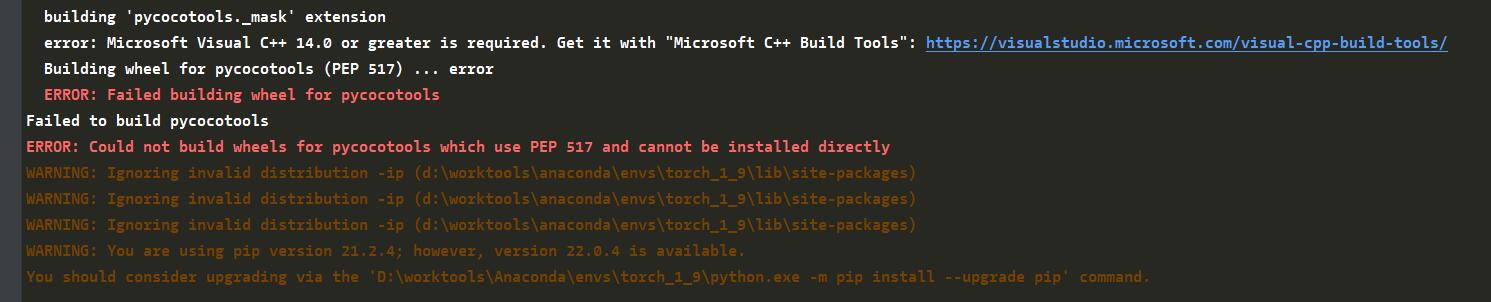
之后安装mim命令,通过这个命令可以下载预训练模型和配置文件。
1 | pip install openmim |
4. 使用MMDetection进行一次目标检测推理
经过前面三个步骤,MMDetection是否已经在windows上安装好了呢?这时候可以使用MMDetection进行一次简单推理,这个过程其实并不复杂。MMDetection项目文件中有一个demo文件夹,这个文件夹下有一个demo.jpg,本文将这张图片当做测试图片,并且使用Faster-RCNN模型进行图片中目标的推理。

因为只是进行推理,所以需要有一个参数文件,参数文件可以直接下载OpenMMLab提供的Faster R-CNN文件,这里就需要使用mim命令进行模型参数文件的下载了。这里使用官方文档中的命令进行下载。首先进入到mmdetection的项目文件夹中。然后命令行运行:
1 | mim download mmdet --config faster_rcnn_r50_fpn_1x_coco --dest . |
下载完成之后可以看到在项目的根目录下多了两个文件,一个是faster_rcnn_r50_fpn_1x_coco.py这个就是faster-rcnn模型的配置文件,从这个配置文件的名字就可以看出来,这是一个以ResNet-50为backbone,使用FPN作为Neck,并且学习率并没有使用特定衰减,在coco上进行训练的Faster-RCNN模型的配置文件。MMDetection的所有模型都依赖这类配置文件构建,这里面写的都是模型的基础参数,比如说Faster-RCNN的backbone或者RPN部分,这里就不再详细展开说明这个配置文件的编写方法了。这个配置文件可以不用管,因为在config/faster_rcnn文件夹中有一个一样的配置文件。
此外还有另一个以pth结尾的文件,这个文件就是Faster-RCNN的参数文件了,在根目录下新建一个文件夹,命名为checkpoints,然后将pth文件拖进去,在根目录下新建一个python文件,这里将其命名为text.py。然后写入代码:
1 | # -*- coding: utf-8 -*- |
之后执行程序,如果安装正确就会在根目录下生成一个result.jpg的图片文件。推理过程中可能出现一个warning,可以不用管。正确推理的图片如下:

5. 使用Faster R-CNN模型在Pascal VOC数据集进行一次训练
MMDetection对COCO数据集支持的很好,可以看到很多和COCO有关的配置,但是VOC好像不多,手边上正好有个VOC2012的数据集,COCO实在太大了,懒得再去下了,所以就用VOC尝试训练了一下,整体流程都是一样的,知道了VOC的配置COCO基本上是一样的。
放置数据集
首先在MMDetection的根目录下创建一个data文件夹,把Pasacl VOC2012放进去,其目录结构如下。
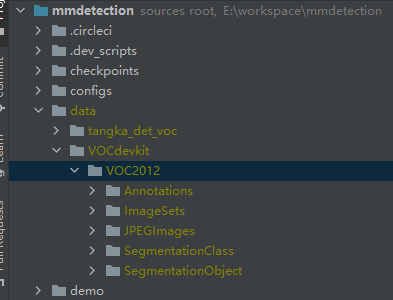
这里不再对Pasacl VOC目录结构和标注文件的结构详解了,只简单说一下,感兴趣的可以自行百度。其中Annotations是xml的标注文件,ImageSets是对数据集进行划分的,以及各个类别进行划分的文件,最重要的是Main文件中的trainval.txt和val.txt,JPEGImages存放的是样本图片。
数据集和图片预处理器的配置
之后在configs文件夹下建立一个文件夹命名为my_configs,当然这里随便起名,只要训练时保持一致就可以。新建一个Python文件,命名为voc2012.py,将以下内容写入。
1 |
|
其实这个文件就是从cofigs/__base__/voc0712.py中抄来的,把和voc2007相关的部分删去了。这个文件就是对数据集以及图片预处理器的配置,横线的上半部分代码是图像预处理部分,如果直接用pytorch编码, 那对应的就是定义transform部分,后面半部分是数据集定义的部分,一定要注意这里的ann_file以及image_prefix路径要和Pascal VOC的路径保持一致,data_root应该写到VOCdevkit而不应该写到VOCdevkit/VOC2012。
超参数的配置
在configs/my_config文件夹下新建一个python文件命名为faster_rcnn_voc2012.py,写入一下内容。
1 | _base_ = [ |
注意这里的_base_列表中的三个值,第一个是模型的配置文件路径,此处并没有自定义模型配置,而是使用的MMDetection自带的配置文件,对配置文件的解析这里就不再详述了,之后会再写一个关于配置文件的文章。第二个参数就是刚刚创建的数据集以及图片预处理器的配置的文件,第三个文件配置了一个训练常用的参数,比如log的等级等,这个文件中剩余的其他部分就是对模型超参数的定义了,比如优化器,学习率等等。
但是注意查看../_base_/models/faster_rcnn_r50_fpn_voc.py中bbox_head下面的num_classes是否为20,如果这里配置出问题的话,模型在训练时的损失会一直是nan。除此之外上述代码中,model定义的部分也有一个地方就是num_classes也改成20(虽然这俩应该是同一个参数)。
这些定义好之后就可以开始训练了。
使用命令或者在pycharm中配置训练参数。
1 | python tools/train.py configs/my_config/faster_rcnn_voc2012.py |
之后就会加载数据,然后开始运行了。看到以下log就是没问题了。

等待训练完成,就可以在work_dirs文件夹下找到对应的训练log和模型参数文件了,然后就可以用推理部分的方法进行推理了。
其实从以上步骤就可以看出了,一个完整mmdetection需要包含一下几个配置项,这些不同的配置项可以写入到不同的文件中,然后使用__base__引入到一个文件中,这几部分分别是数据集的配置文件、transform的配置文件、模型的配置文件以及训练超参数的配置。
当然MMDetection也支持完全的自定义模型结构,就是使用PyTorch那种方式编写模型,数据集也可以用类似的方式定义。
6. MMDetection学习资料
MMDetection最好的学习资料就在MMDetection的官方知乎上,里面写了很多关于模型、数据集配置的教程,其实这些文件在mmdetection根目录的docs文件夹下也有,zh_cn就是中文版本的教程,毕竟商汤是中国的公司,中文教程还是很好获取的。看官方给出的文档其实就是一种最快的学习方式。